Security Monitoring Fundamentals
This section will cover the fundamentals of security monitoring.
Table of Contents
- Introduction
- What is a SOC
- What is a SIEM
- Data Flows Within a SIEM
- Benefits of Using a SIEM
- Introduction to the Elastic Stack
- ELK Stack Overview
- Using Kibana
- The Triaging Process
- The Ideal Triaging Process
- Initial Alert Review
- Alert Classification
- Alert Correlation
- Enrichment of Alert Data
- Contextual Analysis
- Incident Response Planning
- Consultation with IT Operations
- Response Execution
- Escalation
- Continuous Monitoring
- De-escalation
- The Ideal Triaging Process
Introduction
Monitoring is a crucial part when it comes to detecting threats and compromises. There are many tools and ways to do this such as using a Security Information and Event Management (SIEM) system.
What is a SOC
A Security Operations Centre (SOC) is an essential facility that houses a team of security experts for continuous monitoring and evaluating of an organisation's security status.
The main objective of a SOC team is to identify, examine, and address any cybersecurity incidents by using different tools and procedures.
A SOC mainly consists of security analysts that are constantly looking to detect, assess, respond to, report on, and prevent cybersecurity incidents. Depending on the capabilities of the SOC, other responsibilities can be malware analysis or forensics analysis.
A SOC consists of diverse roles and responsibilities. Some roles are:
| Role | Description |
|---|---|
| SOC Director | Responsible for the overall management and strategic planning of the SOC. |
| SOC Manager | Oversees day-to-day operations, manages the team, coordinates incident response efforts, and ensure smooth collaboration with other departments. |
| Tier 1 Analyst | Known as "first responders", monitors security alerts and events, triages potential incidents, and escalate to higher tiers for further investigation. |
| Tier 2 Analyst | More experienced analysts, performs in-depth analysis of escalated incidents, identifies patterns and trends, and develop mitigation strategies to address security threats. |
| Tier 3 Analyst | The most experienced analyst, provides advanced expertise in handling complex security incidents, conducts threat hunting activities, and collaborates with other teams to improve the organisation's security posture. |
| Detection Engineer | Responsible for developing, implementing, and maintaining detection rules and signatures for different security tools such as SIEM, IDS/IPS, and EDR solutions. |
| Incident Responder | Responsible for active security incidents, carries out in-depth digital forensics, containment, and remediation efforts to restore affected systems and prevent future occurrences. |
| Threat Intelligence Analyst | Gather, analyses, and disseminates threat intelligence to help the SOC team understand the threat landscape and proactively defend against emerging threats. |
| Security Engineer | Develops, deploy, and maintains security tools, technologies, infrastructure, and provide technical expertise to the team. |
| Compliance and Governance Specialist | Ensures that the organisation's security practices and processes adhere to relevant industry standards, regulations, laws, and best practices. |
| Security Awareness and Training Coordinator | Develops and implements security training and awareness programs to educate employees about cybersecurity best practices and promotes a culture of security. |
Depending on the organisations, the titles and description can be vastly different. The above table provides a rough overview of the different roles in an SOC.
What is a SIEM
A Security Information and Event Management (SIEM) is a utility that combines security management and supervision of security events.
SIEM tools offers a wide range of core functionalities, such as collection and administration of log events, examine log events and supplementary data from various sources, visual summaries, and more.
As a SIEM is able to consolidate information into a central location, it can help in detecting attacks and increase efficiency during incident response.
A SIEM works by gathering information from different data sources such as workstations, servers, network devices, and more. The data is then standardised and consolidated for analysis.
Some use cases for a SIEM in a business can be log aggregation and normalisation, threat alerting, contextualisation and response, and compliance.
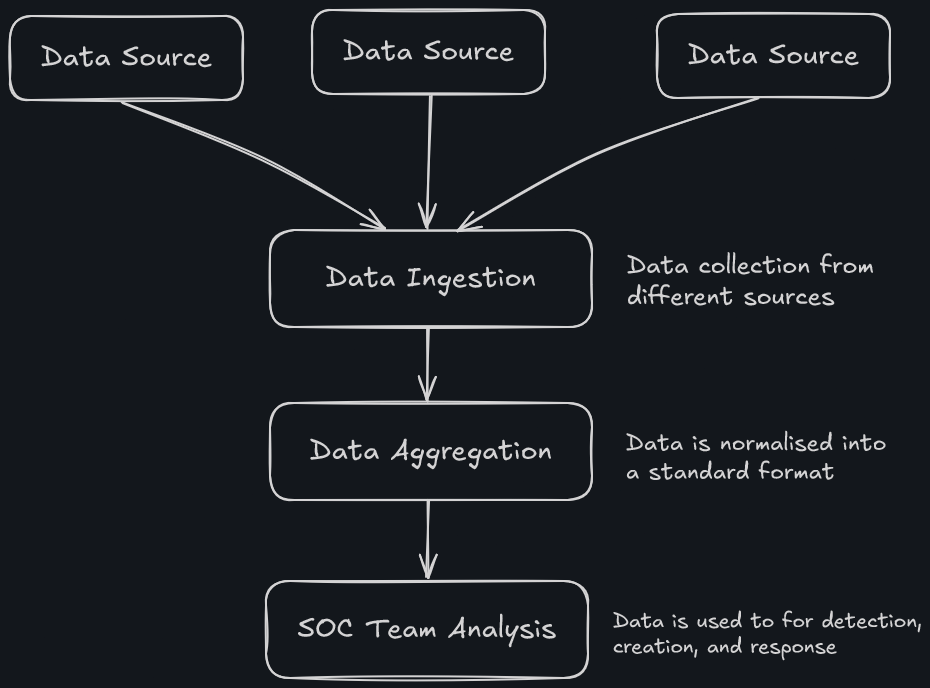
Data Flows Within a SIEM
The following is how data flow within a SIEM until it is ready for analysis.
- SIEM solutions ingest logs from various data sources. Each SIEM tool possesses unique capabilities for collecting logs from different sources. This process is known as data ingestion or data collection.
- The gathered data is processed and normalised to be understood by the SIEM correlation engine. Raw data must be written or read and be converted into a common format from various datasets. This process is known as data normalisation or data aggregation
- The SOC team utilises the normalised data collected to create various detection rules, dashboards, alerts, and incidents. This allows the team to identify and respond to incidents.
Benefits of Using a SIEM
Deploying a SIEM has great advantages as it outweighs the potential risks associated of not having one.
Without a SIEM, there will not be a centralised perspective on all logs and events, which can result in overlooking crucial events and accumulating a large number of events awaiting investigation.
Having a SIEM can improve the incident response process, efficiency, and a centralisation location for event management.
Introduction to the Elastic Stack
The Elastic stack, created by Elastic, is an open-source collection of mainly three applications - Elasticsearch, Kibana, and Logstash (ELK).
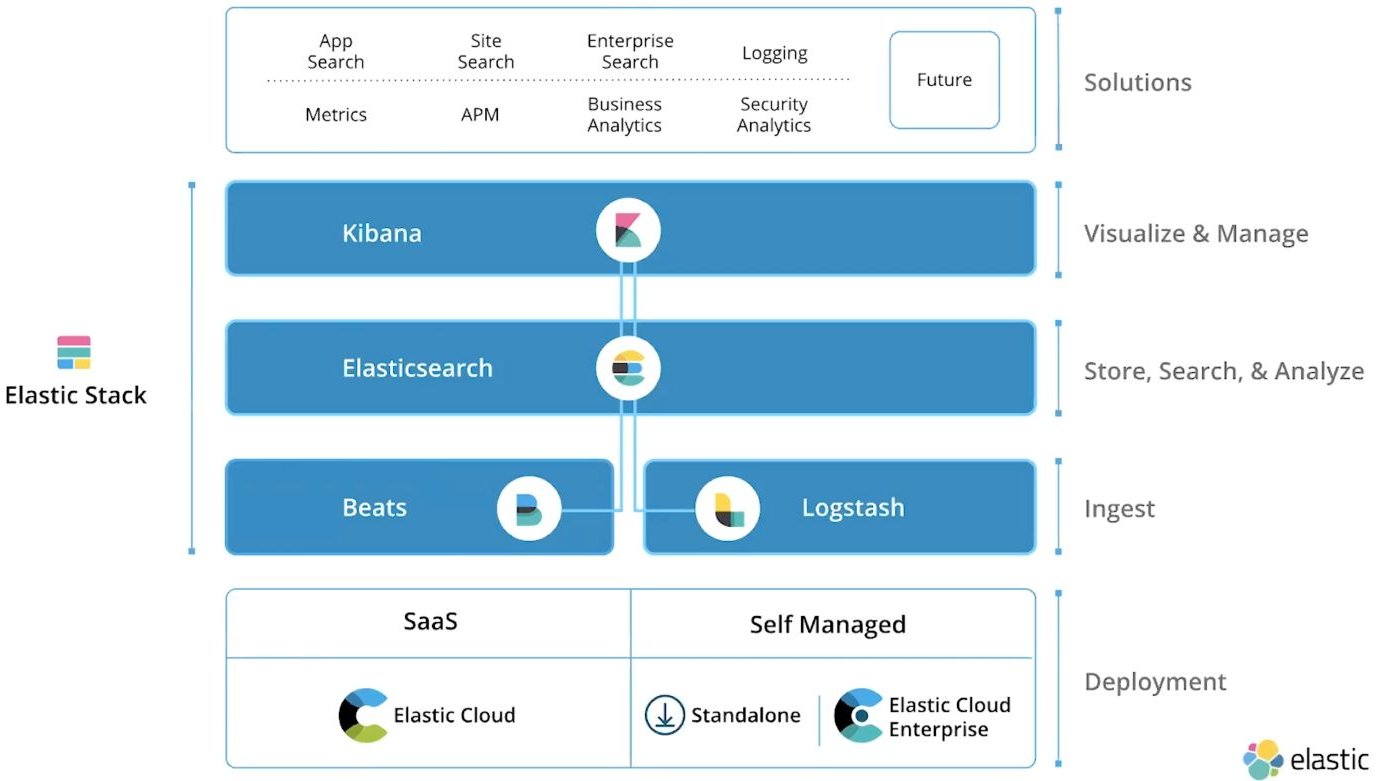
It offers users comprehensive search and visualisation capabilities for real-time analysis and exploration of log file sources.
https://www.elastic.co/elastic-stack
ELK Stack Overview
The Elastic stack consists of mainly three applications - Elasticsearch, Logstash, and Kibana.
Elasticsearch is a distributed and JSON-based search engine, designed with RESTful APIs. It is a core component of the ELK, handling indexing, storage, and querying.
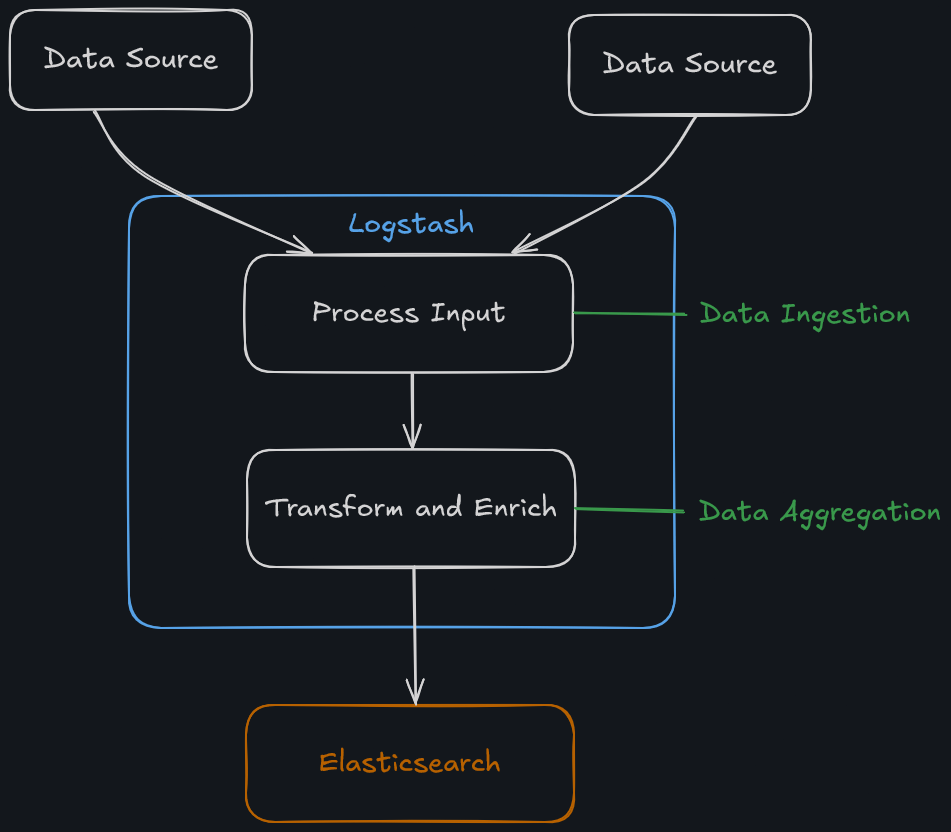
Logstash is responsible for collecting, transforming, and transporting log file records. It is able to consolidate data from various sources and normalise them.
Logstash operates in three main areas:
- Process input - It is also to ingest log file records from remote locations, converting them into a format that machines can understand. Different input methods can be used to receive the records, such as reading from a flat file, a TCP socket, or directly from syslog messages.
- Transform and enrich log records - After collection, Logstash offers numerous ways to modify a log record format and its contents. Specifically, using filter plugins that can perform intermediary processing on an event, usually based on a condition.
- Send log records to Elasticsearch - Once processed, Logstash will utilise output plugins to transmit log records to Elasticsearch
Kibana serves as the visualisation tool for Elasticsearch documents. It allows users to view and visualise the data stored in Elasticsearch and execute queries through Kibana.
Beats is an additional component in the ELK stack. It is able to be installed on remote machines and are designed be lightweight, single-purpose, and forward logs and metrics to either Logstash or Elasticsearch.
The Elastic stack can be used as a SIEM to collect, store, analyse, and visualise security-related data from various sources.
Using Kibana
Kibana has a feature called Kibana Query Language (KQL). It is a user-friendly query language that is designed specifically for searching and analysing data in Kibana.
The following example is the basic structure for a KQL query. It consists of field:value pairs where the field is the data's attribute and the value represents the data you're searching for.
event.code:4625
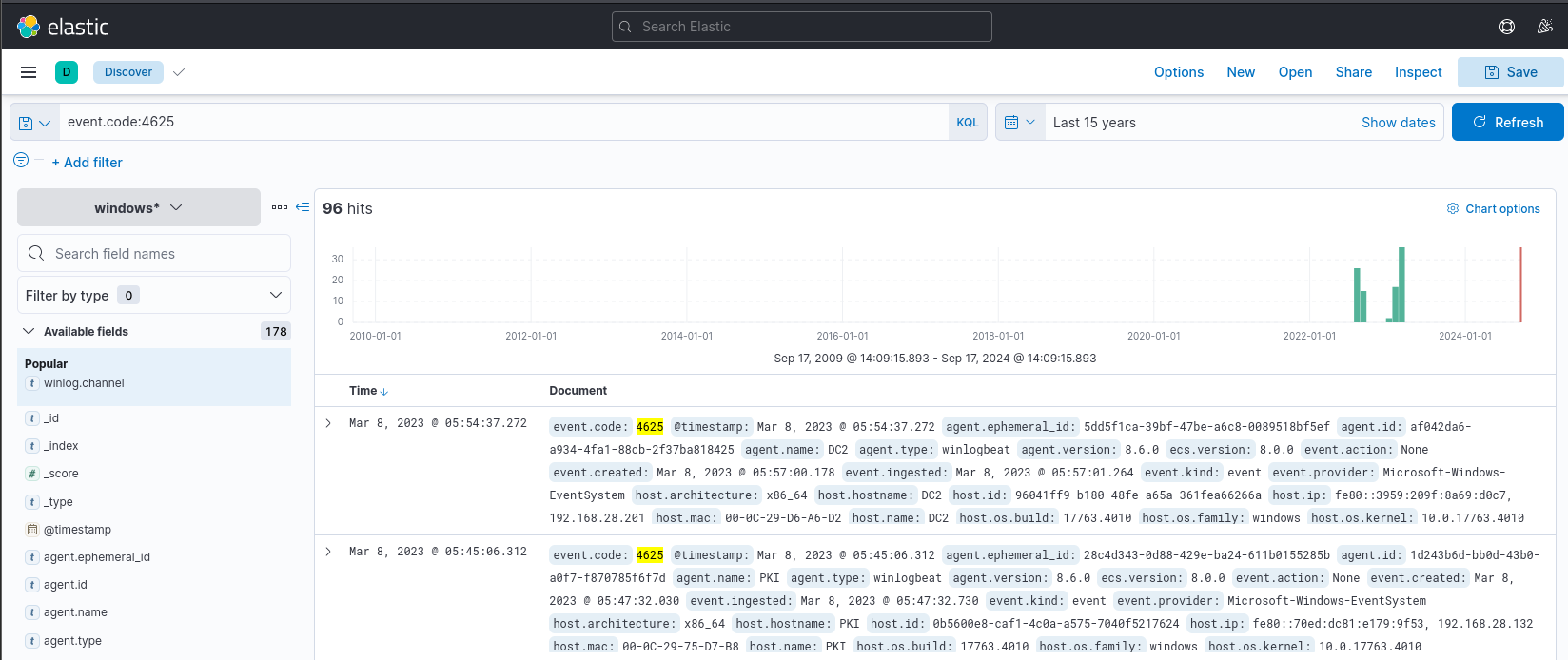
The above KQL query will filter data in Kibana to show events that have the Windows event code 4625. This code is associated with failed login attempts in Windows.
It is also possible to search for a specific term across multiple fields without specifying a field name using free text search.
"svc-sql"
The above query will return any records with svc-sql in any indexed field.
Logical operators such as AND, OR, and NOT can be used. Parentheses can be used to group expressions and control the order of the evaluation for more complex searches.
event.code:4625 AND winlog.event_data.SubStatus:0xC0000072
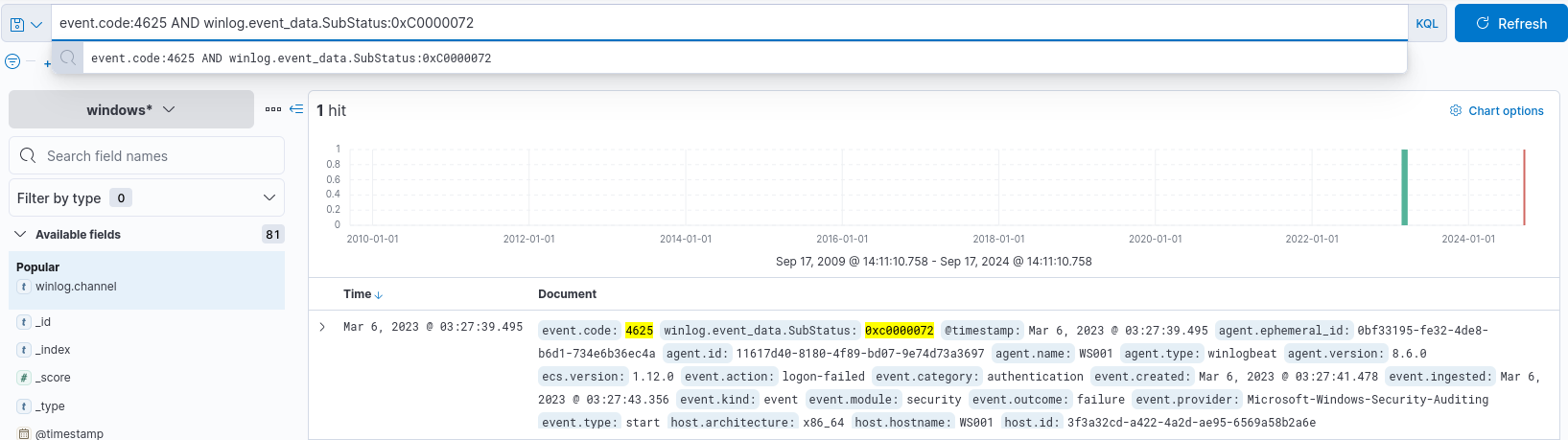
The above query will filter data to show events with the code 4625 (failed logins attempts) and the SubStatus value of 0xC0000072 (account disabled).
Comparison operators such as >, <, <=, and != can be used.
event.code:4265 AND winlog.event_data.SubStatus:0xC0000072 AND @timestamp >= "2023-03-03T00:00:00.000Z" AND @timestamp <= "2023-03-06T23:59:59.999Z"
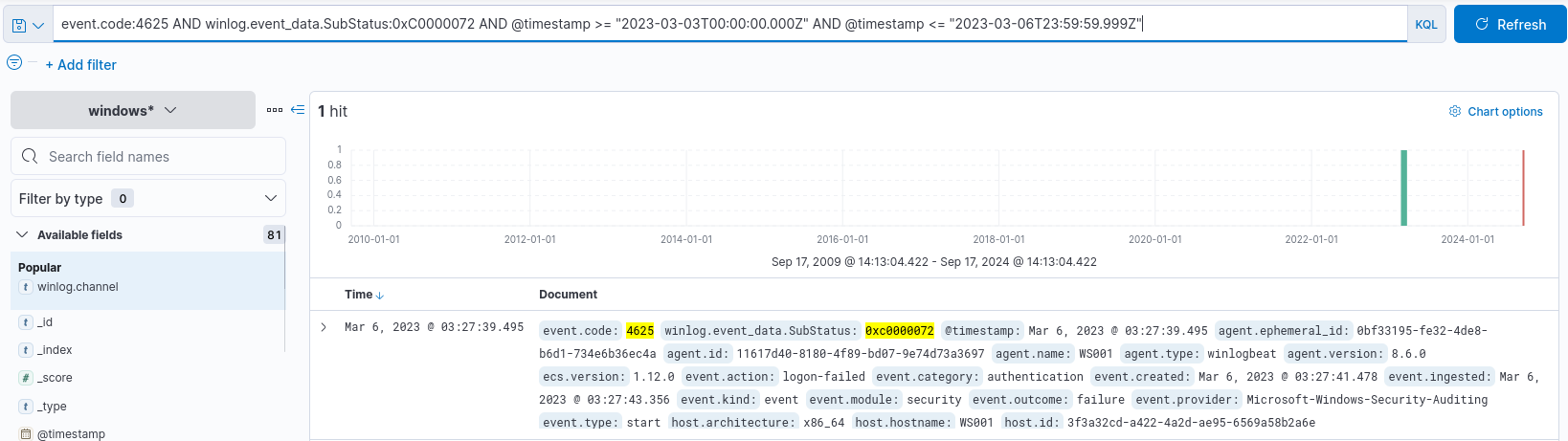
The above query will search for failed logins attempts on windows with the account disabled sub status between the date and time (HH:MM:SS.sss) 2024-03-03 00:00:00.000 and 2023-03-06 23:59:59.999.
Wildcards and regular expressions can be used for patterns in field values.
event.code:4625 AND user.name: admin*
The above query will display any failed login attempts with any account that starts with admin such as, administrator, admin, admin123, etc.
The Triaging Process
Triaging is where someone is investigating on items such as alerts. In an SOC environment, an analyst will usually perform alert triaging.
Alert triaging is the process of evaluating and prioritising security alerts by various monitoring and detection systems to determine the threat level and potential impact on the organisation's systems and data. It involves systematically reviewing and categorising alerts to effectively allocate resources and respond to security incidents.
Escalation is an important part of this process as it typically involves notifying supervisors, incident response teams, or designated individuals within an organisation who has the authority to make decisions and coordinate response efforts.
The Ideal Triaging Process
An ideal triaging process should have the following when an alert is received:
- Initial Alert Review
- Alert Classification
- Alert Correlation
- Enrichment of Alert Data
- Risk Assessment
- Contextual Analysis
- Incident Respond Planning
- Consultation with IT Operations
- Response Execution
- Escalation
- Continuous Monitoring
- De-escalation
Initial Alert Review
The initial alert review is where thorough review of the alert happens by reviewing information such as metadata, source and destination IP address, affected systems, triggered rules/signatures, and other relevant information.
Associated logs from different sources such as firewalls, IDS/IPS, and network traffic is also analysed to understand the alert's context.
Alert Classification
After the initial review is done, the alert can be classified based on items such as severity, impact, and urgency using the organisation's classification system or procedures in place.
Alert Correlation
The alert will be correlated and cross-referenced with related alerts, events, or incidents to identify patterns, similarities, or potential IOCs.
It can be done by using methods such as querying a SIEM or log management system to gather relevant log data.
Threat intelligence can also be leveraged to check for known attack patterns or malware signatures.
Enrichment of Alert Data
Additional information is gathered to enrich the alert data and gain more context. Some examples of information gathered are network packet captures, memory dumps, or file samples associated with the alert.
Other additional information can also be from external threat intelligence, open-source tools, or sandboxes to analyse suspicious files, URLs, or IP addresses.
Reconnaissance on the affected systems is also done to look for anomalies such as network connections, processes, or file modifications.
Contextual Analysis
The analyst should consider the context surrounding the alert, including the affected assets, their criticality, and the sensitivity of the data they handle.
Evaluation of security controls in place such as firewalls, IDS/IPS, and endpoint solutions should be done to determine if the alert indicates a potential control failure or evasion technique.
Other relevant information such as laws, industry regulations, compliance requirements, and contractual obligations should also be reviewed to understand the implications of the alert on the organisation's legal and compliance posture.
Incident Response Planning
An incident response plan should be initiated if the alert is significant. During this process, documentation of alert details, affected systems, observed behaviours, potential IOCs, and enrichment data should be done.
Assignment of incident response team members with defined roles and responsibilities should be done with coordination with other teams if necessary.
Consultation with IT Operations
Assessment should be done if additional context or missing information is required by consulting with IT operations or relevant departments via meetings, collaboration, or other means.
Meetings can be established to gather insights on affected systems, recent changes, or ongoing maintenance activities. Other information can be any known issues, misconfigurations, or network changes that could potentially generate false-positive alerts.
Response Execution
Based on the alert review, risk assessment, consultation, and any other relevant information, determine the appropriate response action needed.
If additional context resolves the alert or identifies it as a non-malicious event, take necessary actions without escalation. If it is a potential security concern or requires further investigation, proceed with incident response action.
Escalation
Identify triggers for escalation based on the organisation's procedures and policies and alert severity. Some examples are compromise of critical systems/assets, ongoing attacks, unfamiliar or sophisticated techniques, widespread impact, or insider threats.
All communications should be documented while providing a comprehensive alert summary, potential impact, and other important information.
In some cases, external entities such as law enforcement should be alerted, depending on the organisation's procedures and laws.
Continuous Monitoring
Continuous monitoring should be done on the situation and incident progress. Open communications with relevant teams, providing updates, findings, or changes should be maintained.
De-escalation
Evaluate the need for de-escalation by reviewing the incident response progress, risk mitigation, if the incident is contained, or if the situation is under control.
Relevant parties should be notified with relevant information such as summary of actions, outcomes, and lessons learned.